

Of course, IT professionals should take a critical look at hyped technologies like microservices [1], [2], [3], [4]. In the end, there are only beneficial or less beneficial choices for a given project. The individual advantages and disadvantages in the particular project should be the focus. After all, it hardly makes sense to choose cool approaches that do not help the project. It makes just as little sense to rule out uncool approaches from the outset, even though they may solve a specific problem.
But hype doesn’t just happen. To better understand the benefits, it makes sense to trace the hype’s origins. To do this, first take a look at the situation before the microservices era: Back then, there were only deployment monoliths. Some of these monoliths had such large amounts of code that compiling alone sometimes took 10 or 20 minutes and took a long time for the application to start. Add to that the times for unit and other tests. As for the tests, the application may have to be started several times. At some point, productive work is hardly possible because programmers have to wait so long until the results of their work are visible.
If you actually develop and test the code, such times are hardly acceptable. Change simply takes far too long. Then there are complex integrations with other systems or complicated runtime environments, such as application servers. They have to be configured, which further lengthens the cycles and makes the path to production even more difficult.
In my first talks about microservices, I asked the audience whether they knew of projects with deployment units that were too large or projects with deployment units that were too small. There seemed to be many projects with too large deployment units, but practically hardly any projects with too small deployment units. At least at that time, it certainly made sense to reduce the size of the deployment units.
The origin
A good source on the origin of the hype and the history of microservices is Wikipedia [5]. According to this, there was a software architecture workshop in 2011 where several participants described a new architectural style. In 2012, the term “microservice” was invented in the next workshop in this series. Participants included, for example, Adrian Cockcroft (Netflix), James Lewis (ThoughtWorks), and Fred George (freelancer). All three already had a lot of experience and were working on important projects. They certainly did not choose the microservices approach to create new hype, but to solve real problems.
The specific problems in their projects were similar, but there were also differences: While a cloud strategy was very important for Netflix, for example, that wasn’t as strongly the case for the other projects. Some of the projects need to scale, but sometimes in different areas: scaling the team size or the software to multiple servers.
Solutions differ: Netflix relies on synchronous communication and services that are so large that a whole team is busy with development. Fred George, on the other hand, recommends asynchronous communication and microservices that are no more than a few hundred lines in size and can be rewritten very easily.
So, there has never been one true microservices concept, but rather different approaches solving different problems right from the start. Even today, the microservices approach is still interpreted and implemented very differently.
Modules
But what are microservices all about? At their core, microservices are a different kind of module and compete with modularization approaches such as JARs, Maven projects, or Java Namespaces. Partitioning like the one in Figure 1 can be implemented as microservices – or with a different modularization approach.
Fig. 1: Modules of an application can be microservices – or other types of modules.
There are significant differences between microservices and other options:
- In a deployment monolith, it can happen that you use some existing class in new code in some other package. This can create a dependency between packages that is not actually desired. This dependency is not intentional. It may not even be noticed because it is hidden in the code and dependencies between packages are not obvious. This leads to a deployment monolith having a large number of unwanted dependencies after some time. Of course, an architecture management tool, for example, can avoid this. But if no precautions have been taken, the dependency chaos in the architecture is unstoppable. On the other hand, if the modules are microservices, they communicate with each other through an explicit interface, e.g., via REST. So, you have to explicitly introduce a dependency from one microservice to another using the interface. This prevents dependencies from creeping in just because you use some class by mistake.
- For operations, the individual modules are visible because they are separate processes. In a deployment monolith, on the other hand, all modules are housed in a single process. This means that in addition to deployment, other operational aspects such as metrics and security can be oriented to individual modules.
Because microservices raise the question of a sensible division of a system, microservices have brought modules back to the core of the discussion. This has given rise to the idea of the modular monolith, because a deployment monolith can also be divided into modules. It should even be modularized, after all, a system without modules would be almost impossible to maintain. If the microservices hype has contributed to the fact that modules as a fundamental architectural concept are being paid more attention to again, that is already worth a lot. If there is a trade-off between different modularization approaches, that’s great.
This raises an important question: If so many deployment monoliths are poorly structured, why should the next deployment monolith be structured any better? The point is not to dismiss deployment monoliths in general as bad. After all, there are well-structured deployment monoliths. But with the large number of poorly structured deployment monoliths, you have to ask and answer the question – for example, by using an architecture management tool. Microservices have the advantage that the partitioning is enforced, at least.
Domain-Driven Design
Of course, the question arises as to how a reasonable division into modules can be achieved. Characteristics of a good partitioning like loose coupling are known to everyone – but achieving them is not so easy. One possibility is DDD.
Domain-Driven Design (DDD) [6] experienced its first flowering circa 2005. At that time it was perceived as a guide to the design of object-oriented systems. Classes became repositories, services, entities or aggregates. DDD helped the fine-grained design of systems at the class level.
But this area is only one part of DDD, the tactical design. Nowadays, the focus is much more on strategic design. This involves the division of systems into bounded contexts. A bounded context has its own domain model that is separate from the other domain models. For example, there might be one domain model for order delivery and another for payment. These two domain models are completely different: for example, payment is about payment options, the creditworthiness of a customer, or the prices and tax rates of goods. For delivery, the focus is on logistics service providers, the customer’s delivery address, or the size or weight of the goods. Using the example of goods, it is clear that the domain models have domain objects with the same label, but model different facets of these domain objects – prices and tax rates in one bounded context, size and weight in the other.
This coarse-grained modularization and decoupling is perhaps the most important trend that microservices have set in motion. Databases with hundreds of tables, each with a multitude of columns as well, is an indication that a domain model has become far too complex and needs to be split up. That’s where bounded contexts can help. Of course, this also applies if no microservices are used at all. So, microservices have also initiated a discussion in this area that is relevant beyond microservices.
Long-term architecture
Many systems survive longer than originally planned. Systems must therefore be built in such a way that they remain maintainable and extensible over the long term. Typically, teams try to define and enforce “clean” architecture. Many projects start with such considerations. However, the number of projects that end up successfully using the concepts to create a long-term maintainable system is small. It might make sense to try out a different approach.
Sometimes architects try to identify focal points for change, which are then implemented in a flexible manner. But an estimate of change frequencies can only be based on historical data. The future, however, is difficult to predict in principle. Architectures often have flexibilities in exactly the wrong place, which only unnecessarily increase the complexity of the system. In places that are actually changed, flexibility is missing. In the end, the system is even more difficult to change.
A different approach can be implemented with microservices: The functional division according to bounded contexts is fundamental. Payment and delivery of goods will always be part of an e-commerce system. If this should no longer be the case, software conversion is probably still the smallest problem. From a functional point of view, this division can remain stable in the long term. DDD does not aim at long-term stability at all, but at a functionally correct division. But this is perhaps the best way to achieve maintainabilityin the long term.
For technologies, however, there must also be a way to keep the system adaptable in the long run. After all, any technology a project chooses will sooner or later become obsolete. At some point, there will be no more security updates and migration to a new technology becomes mandatory. The system should be divided into small units that can be migrated independently to a new version of a technology or to a new technology. This way, large, risky technology updates can be avoided.
In other areas, there are successful approaches to combining old and new technologies. Modular synthesizers consist of modules that can be combined to produce sounds. One standard for the modules is Eurorack [7]. It defines the communication between the modules for example to control the modules and for timing and of course for the audio signal. The standard also defines aspects for operation such as the size of the modules and the supply voltages. The standard has been around since 1996, and there are now 5,000 modules, some of them radically different, all of which can be combined. Of course, the modules sometimes use technologies that did not exist in 1996 – almost 25 years ago. Modern and old technologies can be combined without any problems.
Microservices allow a similar approach: A microservices system only has to standardize communication – for example, with REST or with a messaging system. In addition, operation must be ensured by appropriate rules: For example, microservices can be implemented as Docker containers and have standardized interfaces for metrics or logging.
Thus, a microservices system enables heterogeneous technology stacks, because any technologies can be used in the Docker containers. This supports updating to a new technology: an update can be done gradually for each individual microservice. The approach reduces the risk: if there are difficulties with the new technology, they occur only in the microservices that have already been updated, and you can start with a single microservice first. Microservices for which an update is not worthwhile do not have to be migrated to the current technology, saving time and effort.
Such a step-by-step migration can only work if heterogeneous technology stacks are possible. However, this is only the case with microservices, so better support for technology updates is a crucial difference.
Continuous Delivery
Continuous delivery of software [8] has obvious advantages. For example, a change in production much faster if the software is delivered on a regular basis. Therefore, the time to market improves. Meanwhile, one study [9] proves that there are many more advantages. For example, teams that deploy often can resolve a service failure more quickly. Since a deployment also represents a rebuild of a service, this result is not so surprising. Equally unsurprising is that deployments fail less often when you deploy often. After all, not only are the deployed changes smaller, but teams have more practice deploying.
But Continuous Delivery has other benefits: Teams that deploy often invest 50 percent of their time working on new things, compared to 30 percent for other teams. In return, they work less on security issues, bugs or end-user support. Continuous Delivery improves team productivity. The study shows that companies with Continuous Delivery are more successful in the market and have less employee burnout. The reason for these benefits is presumably that by increasing deployment speed, current problems in the software development process become obvious and can then be optimized away. Furthermore, with frequent deployment, it must be made clear under what conditions changes will be put into production. In addition, the process must be easy to execute and reliable. This kind of environment is more pleasant for employees as well.
The study also shows how often teams should deploy: Low performers deploy between once a month and once every six months, while elite performers deploy several times a day.
A project that deploys once a quarter should be changed to deploy multiple times a day to take advantage of the many positive effects of Continuous Delivery. In an example scenario, the development phase was followed by ten weeks of testing and then a release over the weekend. In this scenario, if tests were accelerated by a factor of 100 through automation, for example, they would still take four hours. Deployment would still take two hours after an acceleration by a factor of four. Then you would be at six hours for a deployment. To deploy several times a day, one would still have to achieve a factor of two or three. Figure 2 shows the time required in relation.
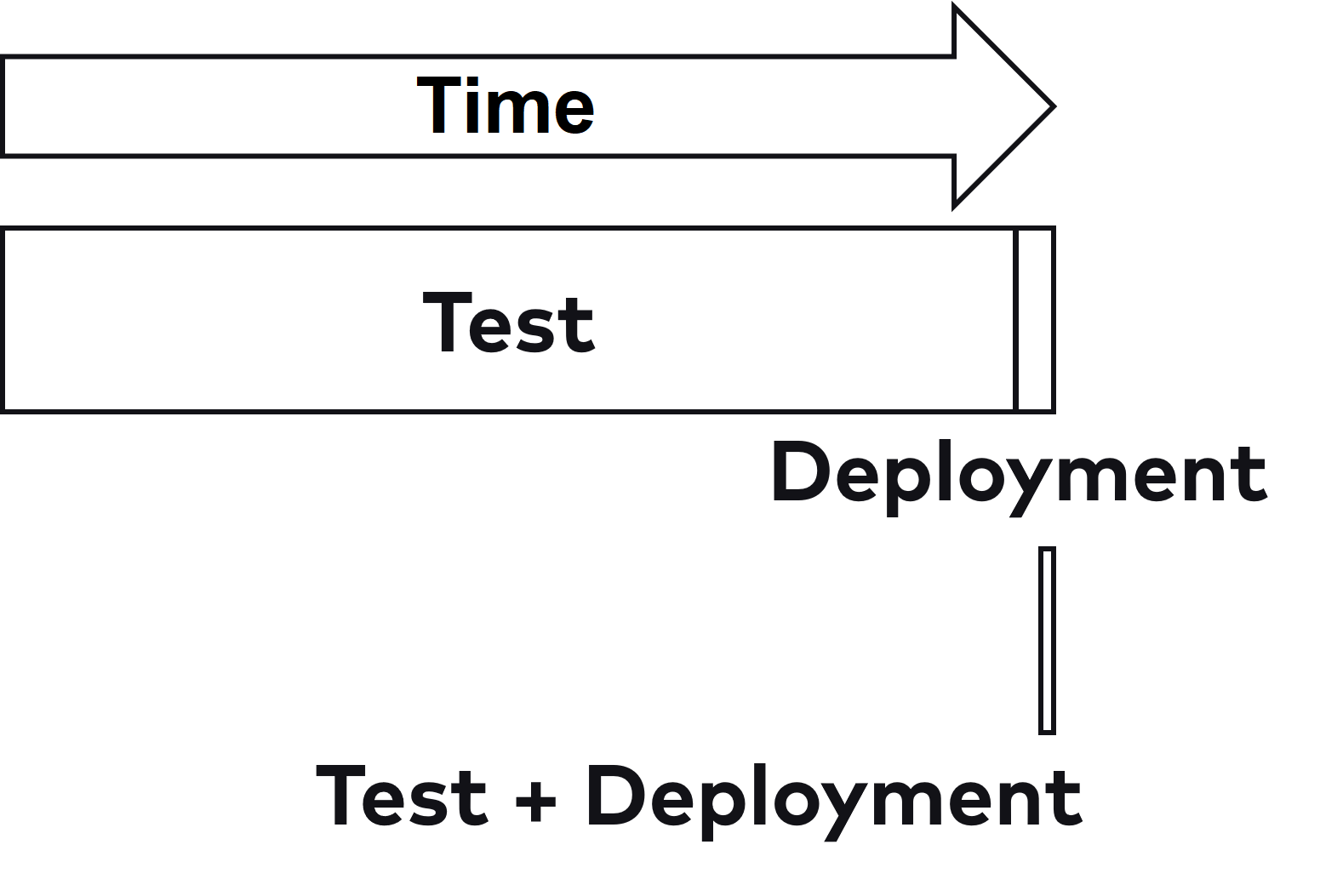
Fig. 2: The release speed must be massively increased
Because of the extreme acceleration factors required, it is hardly conceivable that a strategy that focuses only on optimizing and automating existing processes will lead to the desired success. In fact, the cited study shows that improvements are needed in various areas to increase the speed of deployments. One of the measures is a decoupled architecture. Microservices are one approach to this. Without splitting them into separately deployable modules, the goal of several deployments per day hardly seems achievable, even though it has so many positive effects. Automation and optimization alone can hardly speed up tests that much. But if you change the architecture so that part of the system can be tested and deployed separately, the problem becomes easier to solve.
This scenario also shows that the entire deployment pipeline of the microservices must be independent – including and especially the tests. If the architecture is replaced by microservices, but the monolithic test approach is retained, then nothing changes.
Continuous Delivery shows that microservices in isolation do not solve all problems, but that optimization is possible, for example through automation. On the other hand, high deployment speeds for complex systems can only be achieved if the system is divided into separately deployable units such as microservices.
Organization
Microservices are an architectural approach, but they can also have organizational implications. Traditional organizations often form teams based on technical skill sets, such as a UI team and a backend team.
However, Conway’s law states that the architecture of the system copies the communication structures. Accordingly, this division would result in a UI component and a backend component. This does not fit with the functional division that DDD preaches. This is why the Inverse Conway Maneuver exists in the microservices world. Domain-specific components such as a bounded context are assigned to a team.This way, the organization follows the targeted domain-oriented architecture in teams. Of course, such an approach would also be conceivable without microservices. But microservices add technical independence to the functional independence of the bounded contexts: Each microservice can be deployed separately from the other microservices and use other technologies (Fig. 3).
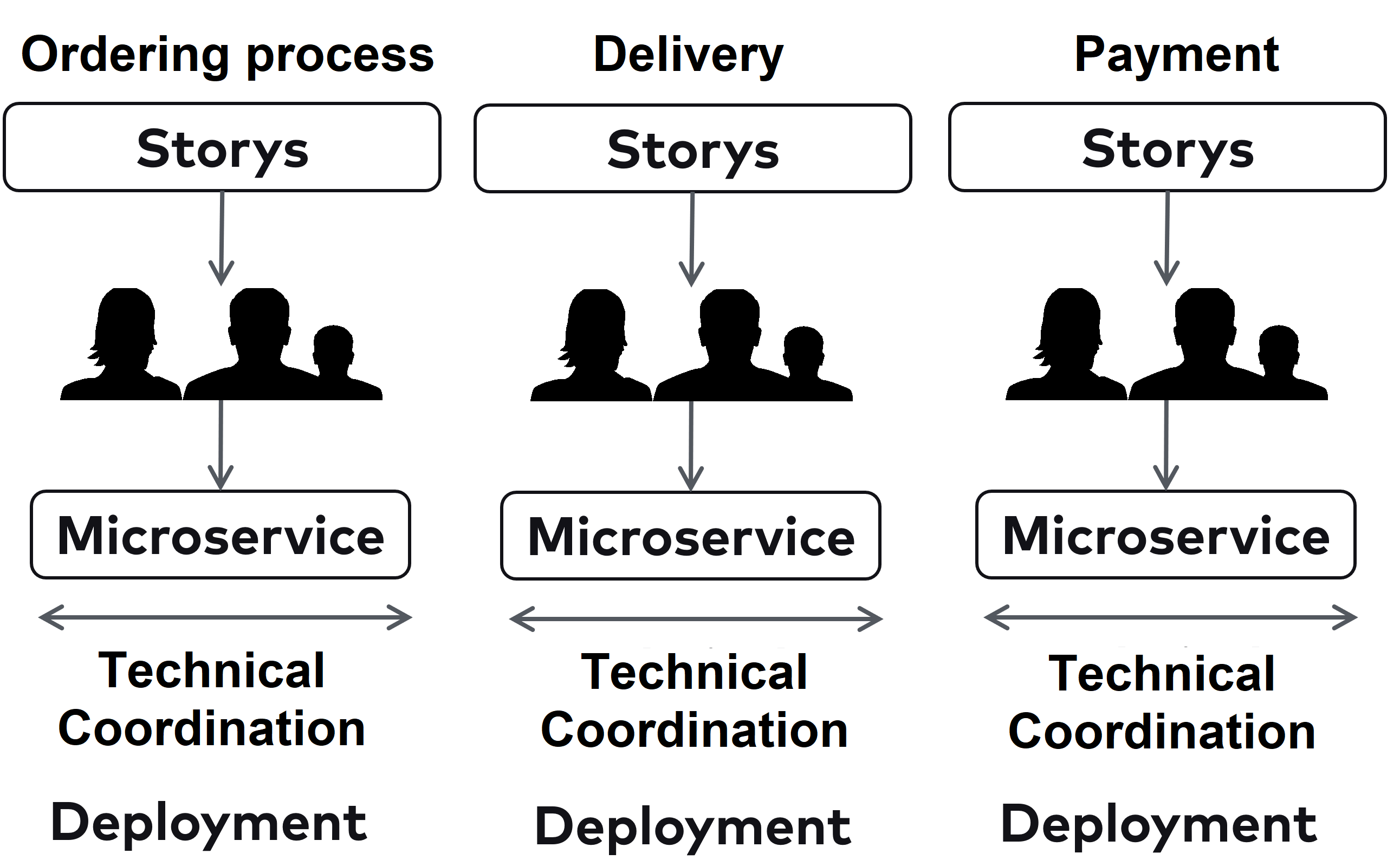
Fig. 3: Microservices complement the domain independence of bounded context with technical independence.
There are several approaches besides microservices and the Inverse Conway Maneuver that all say the same thing at their core:
- DDD calls for a Bounded Context to be developed by a team. Strategic Design describes not only how Bounded Contexts are related, but also possible team relationships.
- Agility demands cross-functional teams. The teams should have as many skills as possible so that they can work as independently of each other as possible. They should also organize themselves, and make as many decisions as possible themselves.
- The book “Accelerate” [10], based on the DevOps study, recommends a loosely coupled architecture to scale teams. Teams should choose the tools. The focus needs to be on developers and outcomes, not technologies or tools. Microservices can support this because they are loosely coupled and different technologies can be used in each microservice. However, other approaches are also conceivable.
Microservices have not introduced the idea that organization and architecture belong together, but this idea is brought into play by different areas.
Microservices can enable independent and self-organized teams. Teams may be limited in their ability to act despite microservices. It is important to trust teams. Only then will they be allowed to make decisions for themselves. This aspect is perhaps even more important than switching the architecture to microservices.
Of course, there are plenty of other reasons for using microservices besides scaling the organization. So it is by no means the case that microservices only make sense for large, complex systems, but they can also be useful in smaller projects, because of the advantages in Continuous Delivery.
Conclusion
Microservices are hyped, but it has died down and turned into the opposite. Regardless of whether you use microservices or not, microservices have changed the discussion about architecture:
- Modules and Domain-Driven Design have become important topics again. This is good, because reasonable modularization is central to system maintainability.
- For a long-lived architecture, microservices offer a good alternative because of the heterogeneous technology stacks.
- Continuous Delivery is an important way to optimize software development. At least in some cases, the necessary deployment speed can only be achieved by using microservices as an architectural concept; but microservices are only one of many optimizations that should be taken.
- The relationship between organization and architecture is not only brought into focus by microservices.
- Thus, microservices provide some interesting food for thought that can be useful even without full microservices architecture. Because in the end, it’s not about chasing hype, it’s about making sensible architecture decisions.
Links & Literature
[1] Wolff, Eberhard: „Microservices: Flexible Software Architectures, https://microservices-book.com/
[2] Wolff, Eberhard: „Microservices Primer“, https://microservices-book.com/primer.html
[3] Wolff, Eberhard: „Microservices – A Practical Guide“, https://practical-microservices.com/
[4] Wolff, Eberhard: „Microservices Recipes“, https://practical-microservices.com/recipes.html
[5] https://en.wikipedia.org/wiki/Microservices#History
[6] Evan, Eric: “Domain-Driven Design Referenz”, https://www.domainlanguage.com/ddd/reference/
[7] https://en.wikipedia.org/wiki/Eurorack
[8] Wolff, Eberhard: „A Practical Guide to Continuous Delivery“, https://continuous-delivery-book.com/
[9] https://cloud.google.com/devops/state-of-devops/
[10] Forsgren, Nicole; Humble, Jez; Kim, Gene: „ACCELERATE
The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations“, IT Revolution Press, 2018



